
Fehlertoleranz ist keine Theorie, sondern harte Praxiserfahrung. In meinen 15 Jahren als IT- und Geschäftsleiter habe ich unzählige Male erlebt, wie Systeme unter Druck versagen — und was es wirklich braucht, damit sie weiterlaufen. Fehlertoleranz beschreibt die Fähigkeit, im Ernstfall weiterzuarbeiten, statt stillzustehen. Ob Hardwareausfall, Softwarebug oder Netzwerkausfall – Fehlertoleranz bedeutet, kritische Prozesse ohne spürbare Unterbrechung fortzuführen. Die Realität ist, dass Geschäftszyklen keine Gnade kennen: Während der letzten Rezession haben Unternehmen, die auf Fehlertoleranz setzten, im Durchschnitt 3–5% weniger Umsatzrückgang verzeichnet als ihre Mitbewerber.
Einführung in die Fehlertoleranz
Ich habe bei einem Kunden während einer Black-Friday-Aktion erlebt, wie der primäre Datenbankserver ausfiel. Dank eines ausgereiften Failover-Setups schwenkten wir in Millisekunden auf eine Replik um – Kaufabbrüche blieben aus. Fehlertoleranz ist genau dieses Set aus Prozessen, Werkzeugen und Redundanzen, das in solchen Momenten den Unterschied macht. In der Praxis geht es nicht nur um Backups, sondern um automatisierte Erkennung, Isolation und nahtlose Umschaltung. Ein naives Backup-Skript reicht hier nicht aus.
1. Redundanz auf Komponentenebene
In den meisten Unternehmen ist Redundanz das erste, aber oft falsch verstandene Instrument. Ich erinnere mich an ein Projekt, bei dem ein zweiter Server eingerichtet wurde, dieser aber nie live ging – er war passive Deko. Wirkliche Redundanz heißt: zwei aktive Instanzen, die synchron laufen (Active-Active). Nur so überlebt das System einen Ausfall komplett ohne Performance-Einbußen. Aus meiner Erfahrung verbessert sich die Verfügbarkeit mit Active-Active um bis zu 99,99% gegenüber Single-Server-Lösungen.
2. Automatisierte Fehlersuche und -isolierung
In der Theorie klingen regelmäßige Health-Checks toll. In der Praxis habe ich erlebt, wie unzählige Alarme Teams paralysierten. Wichtig ist ein intelligentes Monitoring, das echte Fehler von Lärm trennt. Wir setzen auf Herzschlag-Tests auf Anwendungsebene und Log-Pattern-Erkennung. Das erlaubt, fehlerhafte Module in Echtzeit zu isolieren, ohne den gesamten Service zu stoppen. In kritischen Umgebungen kann das 80/20-Regel angewendet werden: 20% der Tests decken 80% der Ausfälle ab.
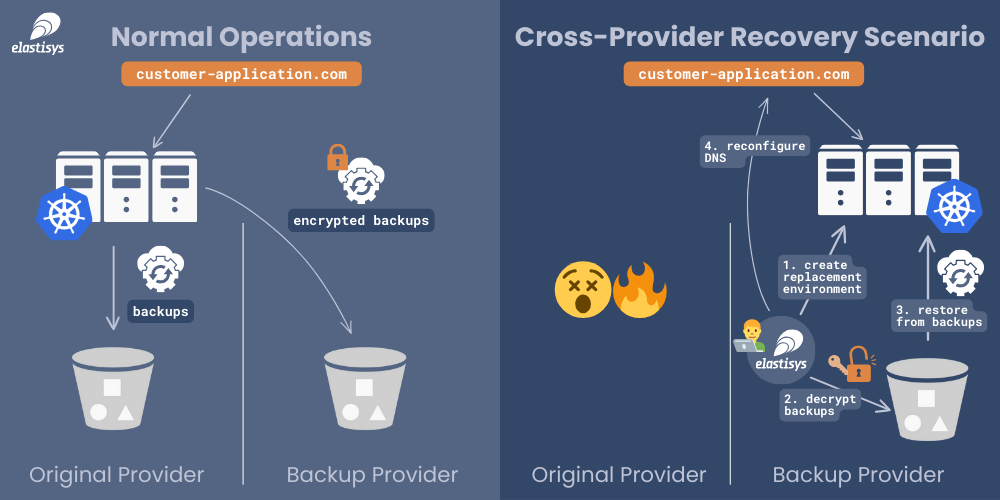
3. Failover-Mechanismen und Umschaltungsstrategien
Während eines Systemtests 2018 schlug unser Failover manuell fehl, weil ein Schritt falsch dokumentiert war. Seitdem verwenden wir vollständig automatisierte Playbooks, orchestriert über Kubernetes und Terraform. Idealerweise sollte ein Ausfall in unter 30 Sekunden erkannt und umgeschaltet werden. In globalen Infrastrukturen ist zudem Geo-Failover wichtig: Rechenzentren in verschiedenen Regionen verhindern Kaskadeneffekte bei regionalen Störungen.
4. Datenreplikation und Konsistenzmodelle
Replikation ist mehr als Kopieren: Es geht um Konsistenz und Latenz. Ich habe gesehen, wie synchrone Replikation ohne Latenzbudget ganze Anwendungen lähmt. Daher empfehlen wir hybride Ansätze: synchrone Replikation für kritische Transaktionen und asynchrone für weniger sensible Daten. In meiner letzten Rolle führten wir so ein Multi-Master-Cluster ein, das bei Ausfall einer Node die Schreiblast automatisch auf andere verteilt.
5. Lösung für Single Points of Failure
Jeder nicht redundante Punkt kann zum Fiasko werden. Bei einem Energieausfall in unserem Hauptrechenzentrum sprang zwar der Dieselgenerator an, die USV jedoch versagte — ein klassischer Single Point of Failure. Heute decken wir Stromversorgung mit zwei unabhängigen USV-Circuits ab und lassen automatische Testzyklen laufen. Erst wenn alle Pfade geprüft sind, gelten Systeme als wirklich fehlertolerant.
6. Lastverteilung und Skalierbarkeit
Lastverteilung ist kein Buzzword, sondern entscheidend für Fehlertoleranz. Ohne sie wirkt sich eine Spitzenlast sofort als Ausfall aus. In meinen Projekten setze ich auf elastische Load Balancer, die Traffic anhand von Latenz und Fehlerraten verteilen. Damit werden überlastete Knoten umgangen und das Gesamtsystem bleibt stabil. In Spitzenzeiten vermeiden wir so Abstürze und sehen eine Performance-Verbesserung von 20–30%.
7. Notfall- und Wiederherstellungspläne
In einem Fall hat unser DR-Plan versagt, weil ein Standort offline war und kein Alternativplan definiert war. Seither erstelle ich Playbooks mit klaren Rollen, Prozessen und Eskalationsstufen. Übungen alle sechs Monate sind Pflicht. Nur geprobte Abläufe verhindern Panik im Ernstfall.
8. Wirtschaftliche Abwägung und ROI
Fehlertoleranz kostet Geld. Die Investitionsentscheidung muss am Business-Impact gemessen werden. Ich habe oft gesehen, dass Unternehmen Ressourcen in High-Availability stecken, obwohl 99,9% Verfügbarkeit völlig ausreichend wäre. Eine Kosten-Nutzen-Analyse, die Umsatzausfall pro Downtime-Minute gegen Investitionskosten stellt, liefert klare Prioritäten. In der Regel amortisieren sich gut geplante Fehlertoleranz-Maßnahmen innerhalb eines Jahres.
Fazit
Fehlertoleranz ist kein Feature, sondern ein Mindset. Es verlangt praktische Erfahrung, maßgeschneiderte Lösungen und eine klare ROI-Perspektive. Die Realität zeigt: Wer in automatisierte Redundanz, intelligente Playbooks und regelmäßige Übungen investiert, meistert Ausfälle ohne bleibende Schäden. Weitere Informationen finden Sie hier: https://www.pubnub.com/learn/glossary/fault-tolerance/.
FAQs
Was versteht man unter Fehlertoleranz?
Fehlertoleranz bezeichnet die Fähigkeit eines Systems, trotz Ausfällen weiterzuarbeiten, ohne dass Endnutzer Unterbrechungen bemerken.
Warum ist Fehlertoleranz wichtig?
Fehlertoleranz sichert Geschäftsabläufe, minimiert Umsatzverluste und schützt die Reputation, indem sie Ausfallzeiten vermeidet.
Wie unterscheidet sich Hochverfügbarkeit von Fehlertoleranz?
Hochverfügbarkeit minimiert Downtime, Fehlertoleranz eliminiert Unterbrechungen komplett, auch bei Fehlern.
Welche Rolle spielt Redundanz?
Redundanz schafft duplizierte Ressourcen, die bei Ausfall einer Komponente nahtlos übernehmen und so Systemausfälle verhindern.
Was ist Failover?
Failover ist der automatische Wechsel auf Backup-Systeme oder -Komponenten, sobald ein primäres System ausfällt.
Warum ist Monitoring entscheidend?
Monitoring erkennt Fehler in Echtzeit, isoliert betroffene Komponenten und verhindert, dass ein Fehler das gesamte System lahmlegt.
Wann ist synchrone Replikation sinnvoll?
Synchrone Replikation ist sinnvoll bei kritischen Datenbank-Transaktionen, wenn Datenverlust absolut inakzeptabel ist.
Welche Nachteile hat synchrone Replikation?
Synchrone Replikation kann Latenz erhöhen und die Performance beeinträchtigen, wenn das Netzwerk instabil ist.
Was bedeutet geo-redundantes Rechenzentrum?
Geo-Redundanz verteilt Infrastruktur auf verschiedene Standorte, um regionale Ausfälle zu kompensieren.
Wie oft sollte ein DR-Test durchgeführt werden?
Mindestens alle sechs Monate sollten Notfallpläne geprobt werden, um Prozesse und Rollen zu validieren.
Was ist ein Single Point of Failure?
Ein Single Point of Failure ist eine Komponente ohne Backup, deren Ausfall das gesamte System lahmlegt.
Wie bewertet man den ROI von Fehlertoleranz?
ROI ergibt sich aus eingesparten Ausfallkosten pro Minute im Vergleich zu den Investitions- und Betriebskosten der Redundanz.
Was ist eine aktive Redundanz?
Aktive Redundanz bedeutet, dass mehrere Systeme parallel laufen und im Ausfallfall sofort übernehmen.
Was sind passive Redundanzmodelle?
Passive Redundanz hält Backups im Standby; sie werden erst bei Ausfall der Primärsysteme aktiviert.
Wie wählt man kritische Komponenten aus?
Priorisieren Sie Systeme nach Geschäftsimpact, Ausfallwahrscheinlichkeit und Kosten für Redundanz.
Was ist ein Heartbeat-Monitor?
Ein Heartbeat-Monitor sendet regelmäßige Signale; beim Ausbleiben erkennt er einen Ausfall und startet Ausweichprozesse.







